
시간
30배 커버리지를 갖는 전형적인 전체 인간 유전체를 처리하기 위해, 다양한 컴퓨팅 플랫폼이 사용될 수 있습니다. 일부 애플리케이션은 신속한 2차 분석을 통해 더 빠른 답변을 요구합니다. 다른 애플리케이션은 단순히 생성되는 데이터의 양으로 인해 빠른 2차 분석의 이점을 누릴 수 있으며, NovaSeq X 임베디드 2차 분석은 이러한 수요를 충족시키기에 충분합니다.
듀얼 플로우 셀 런당 최대 128개 이상의 30배 전장 유전체 시퀀싱(WGS) 샘플을 생성하는 NovaSeq X는 진정한 공장 규모의 기기입니다. 그러나 NovaSeq X의 세련된 쉘에 삽입된 숨겨진 DRAGEN은 즉시 2차 분석을 수행할 수 있으며, 종종 마지막 런 데이터 처리에 소요되는 시간이 다음 런 설정 시간(즉, 세척 및 클러스터링 시간)과 동일할 정도로 빠릅니다.
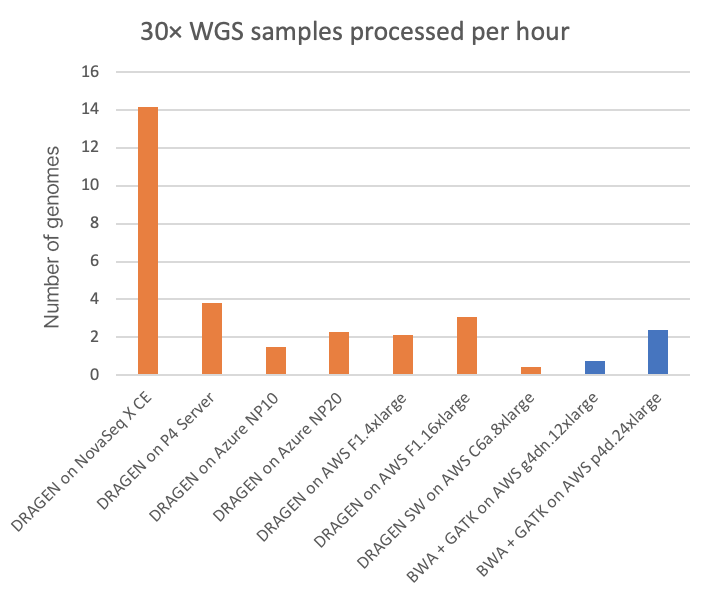
NovaSeq X Plus의 경우, 듀얼 소켓 AMD EPYC 7552(96 x86_64 코어 결합)에서 기기 내 DRAGEN 처리가 수행되며, 이는 4개의 Xilinx Alveo U250 FPGA 카드와 1.5TB RAM도 사용할 수 있습니다. 이러한 상당한 연산 마력을 통해 기기 내 DRAGEN은 약 4분마다 1회 30× WGS 샘플을 완전히 처리된(샘플별 BCL에서 정렬/디업, 정렬 리드, 변이 콜) gVCF로 출력할 수 있습니다. 이 속도는 아래 그림 2의 다른 DRAGEN 구현과 일부 GPU 가속 타사 파이프라인과 비교됩니다.
그림 2에서 NovaSeq X에 내장된 FPGA 가속 임베디드 DRAGEN은 T4 또는 A100 GPU 클라우드 인스턴스에서 각각 거의 20배 또는 6배의 속도를 보여줍니다.
차트에서 다음 사항에 유의하십시오:
- “NovaSeq X CE의 DRAGEN”은 NovaSeq X 기기의 일부인 임베디드 언더더 후드 HPC 컴퓨팅입니다.
- "P4 서버의 DRAGEN"은 Illumina에서 구매할 수 있는 현장 전용 DRAGEN Server의 현재 버전입니다.
- 다른 모든 지표는 Microsoft Azure 및 AWS(Amazon Web Services)의 다양한 종류의 공개적으로 액세스할 수 있는 클라우드 컴퓨팅 인스턴스에서 실행하여 도출되었습니다.
- 소프트웨어 전용 버전의 DRAGEN 파이프라인을 사용하는 “AWS C6a.8xlarge의 DRAGEN SW”와 관련된 것을 제외하고 모든 DRAGEN 실행에는 FPGA 가속이 포함됩니다.
- BWA + GATK 런은 AWS 클라우드에서 두 가지 유형의 GPU 인스턴스 유형에 대해 표시되며, 파이프라인은 가속화된 런타임을 위해 GPU로 이식되고 최적화되었습니다.
비용
대량의 데이터가 처리되는 경우 컴퓨팅 비용도 고려해야 합니다. NovaSeq X 기기에서 DRAGEN 컴퓨팅은 기기 비용의 일부로 포함되므로 NovaSeq X 사용자에게는 사실상 무료로 제공됩니다. 그러나, 시퀀싱 처리량에 대한 컴퓨팅 구성 요소 비용과 기기의 예상 5년 수명을 상각하는 경우, 30배 WGS 샘플당 비용이 발생합니다.
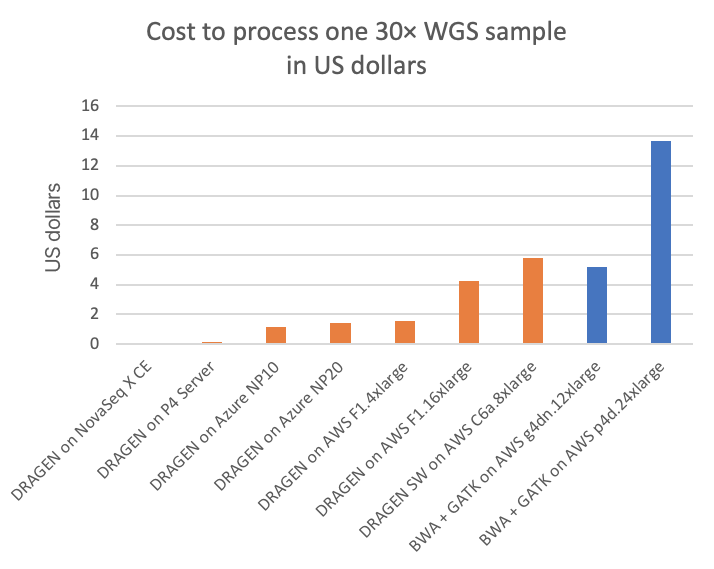
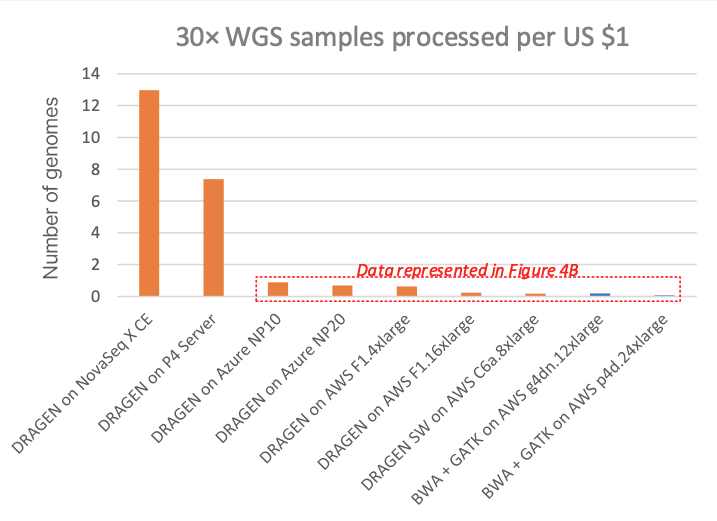
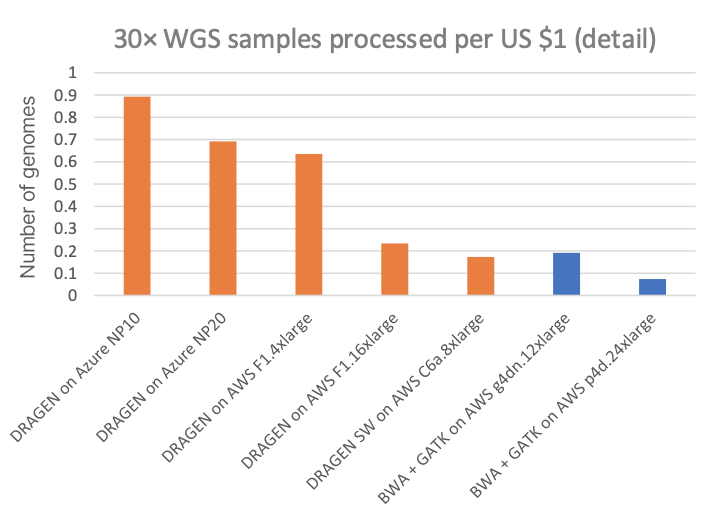
그림 3은 30배 WGS 샘플당 비용으로 다양한 클라우드 컴퓨팅 인스턴스(모든 클라우드 목록에 대해 표시된 "온디맨드" 가격)의 여러 다른 DRAGEN 및 타사 파이프라인과 비교합니다. 그림 4A는 컴퓨팅 달러당 처리할 수 있는 30× WGS 샘플 수를 보여주고, 하위 플롯 그림 4B는 전용 DRAGEN 하드웨어 데이터 포인트가 제거된 그림 4A의 상세도를 보여줍니다(NovaSeq X CE와 DRAGEN P4 Server의 달러당 샘플 처리량이 매우 높아, 클라우드 옵션의 가격 차이를 명확히 보려면 y축 눈금 확장이 필요함).
차트에서 NovaSeq X에 내장된 FPGA 가속 DRAGEN은 T4 또는 A100 GPU 클라우드 인스턴스에 비해 비용 측면에서 각각 최대 60배 또는 170배 이상의 이점을 보여줍니다.
에너지
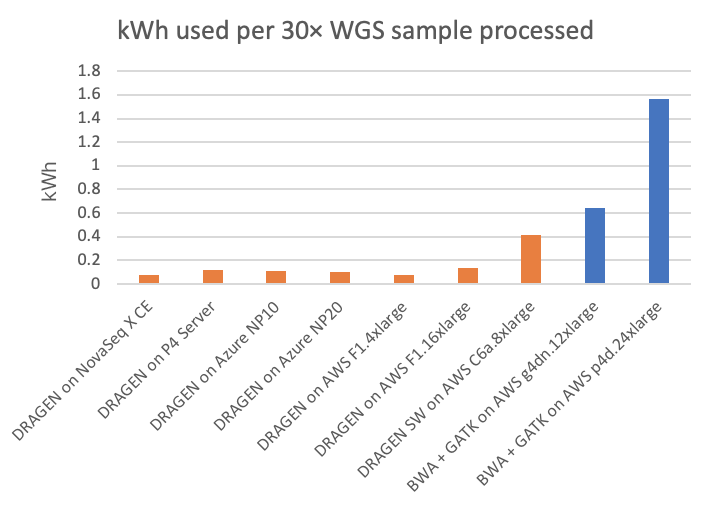
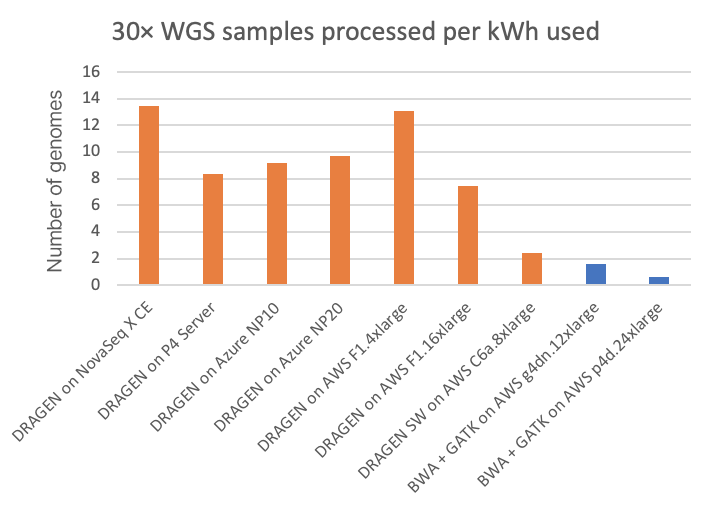
소비 전력은 환경 영향 및 유틸리티 비용과 관련이 있을 뿐만 아니라 2차 분석 컴퓨팅 플랫폼의 폼 팩터를 제한할 수 있기 때문에 관심 있는 요소입니다. NovaSeq X CE 및 P4 서버 DRAGEN 런의 경우, 우리는 DRAGEN 컴퓨팅 플랫폼에서 소비 전력을 직접 측정할 수 있습니다. 우리는 클라우드 플랫폼에서는 게시된 시스템 구성을 기반으로 소비 전력을 추정하고 있습니다. (독자 여러분, 클라우드 소비 전력에 관한 더 정확한 정보가 있는 경우, 여기에 링크된 양식을 통해 당사에 문의하시면 이에 따라 이 기사를 기꺼이 수정할 것입니다.) 30× WGS 샘플당 킬로와트-시간 및 역방향(kWh당 30× WGS) 에너지 사용량은 기기 내 NovaSeq X DRAGEN 및 현장 P4 DRAGEN Server뿐만 아니라 클라우드 컴퓨팅 인스턴스에서 실행되는 다른 DRAGEN 및 타사 파이프라인에 대해 각각 그림 5 및 그림 6에 나와 있습니다.
차트에서 NovaSeq X의 내장된 FPGA 가속 DRAGEN은 T4 또는 A100 GPU 클라우드 인스턴스에 비해 에너지 효율성 측면에서 각각 최대 8배 또는 20배 이상의 이점을 보여줍니다.
풋프린트
특히, NovaSeq X 기기에는 단일 표준 200–240 볼트 AC, 50/60 헤르츠, 15암페어, 단상 전원 플러그만 있으며, 이 플러그에서 시퀀싱 하드웨어(레이저, 히터, 펌프 등)와 DRAGEN 컴퓨팅이 모두 전력을 끌어옵니다. 또한, 내장된 DRAGEN 컴퓨팅으로부터 생성된 열은 시퀀싱 자체의 화학적 또는 생물학적 반응에 부정적인 영향을 미치지 않는 정도로 제거 가능해야 합니다. FPGA 가속 DRAGEN은 유전체당 낮은 에너지 소비와 컴팩트한 HPC급 컴퓨팅 성능을 통해 이러한 간소화된 설치 공간을 가능하게 합니다.
결과의 품질
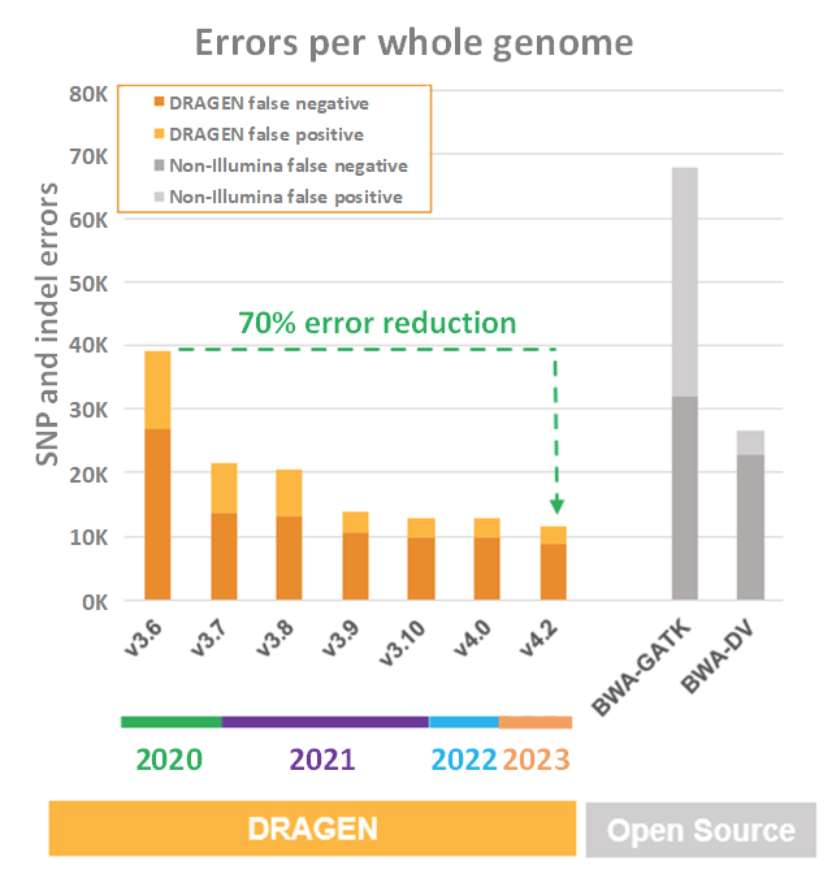
NovaSeq X 기기 내 DRAGEN 컴퓨팅이 위에 자세히 설명된 모든 처리량, 비용, 전력 및 설치 공간 비교에서 우위를 차지한다는 점만으로도 충분히 인상적입니다. 그러나 이러한 차트만으로는 DRAGEN 가속화에 FPGA가 선택된 이유를 완전히 설명해주지 못합니다. DRAGEN 가속화에 FPGA가 선택된 이유는 우수한 처리량, 비용, 전력 효율 및 공간 효율 특성 덕분에 시퀀서 판독 데이터에서 최대한 유용한 정보를 추출하는 작업에 더 많은 연산 집약적 알고리즘을 적용할 수 있기 때문입니다. DRAGEN은 이 분야에서 탁월한 역량을 발휘하여 이제는 스스로 가장 강력한 경쟁자가 되었으며, DRAGEN 파이프라인의 연속 출시마다 정밀도, 민감도, 특이도를 끊임없이 끌어올리고 있습니다. 아래 그림 7은 제3자 2차 분석 파이프라인(BWA + GATK 및 Google의 Deep Variant)과 여러 세대의 DRAGEN에 대한 위양성 및 위음성 지표를 요약하여 보여줍니다.
결론
CPU 및 GPU 제조업체는 유전체 워크로드와 관련하여 제품 오퍼링을 지속적으로 개선하고 있으며, CPU 또는 GPU의 프로그래밍 파이프라인은 FPGA에 비해서 개발자의 노력이 덜 필요합니다.
그럼에도 불구하고 Illumina 엔지니어는 유전체 파이프라인을 FPGA 가속화 플랫폼으로 이식하는 데 많은 노력을 기울였으며, 이러한 FPGA 가속화는 고객이 중요하게 여기는 모든 지표에서 여전히 상당한 이점을 보여주고 있습니다. 이는 결과적으로 FPGA 가속 DRAGEN 파이프라인을 사용할 수 있는 Illumina 고객에게 실질적인 이점이 됩니다.
컴퓨팅 비용, 전력 및/또는 총 소요 시간이 현재 유전체학 분야에서 목격되고 있는 진전을 갑작스럽게 둔화시키거나 중단시킬 문제와 같이 유전체학이 직면하고 있는 임박한 컴퓨팅 절벽에 대해 업계에서 많은 논의가 이루어져 왔습니다. FPGA 가속을 사용하는 경우 이러한 절벽이 예상되지 않습니다. 기기 내 FPGA 가속 DRAGEN은 5분 이내에 30배의 인간 유전체를 완전히 분석할 수 있으며, 컴퓨팅 비용은 10센트 미만이며, 에너지 소모량은 가장 효율적인 테슬라 모델 3가 도로에서 0.5km 주행하는 데 필요한 에너지와 거의 동일합니다.
DRAGEN의 탁월한 처리량, 비용, 전력 효율 및 공간 효율 지표는 그 자체로도 인상적입니다. DRAGEN이 이러한 지표를 달성하는 동시에 다른 NGS 2차 분석 파이프라인보다 더 나은 결과 품질(정밀도, 민감도, 특이도)을 지속적으로 개선한다는 점은 더욱 인상적입니다. CPU, GPU 및 FPGA가 진화함에 따라 DRAGEN 팀은 사용자에게 더 나은 정확한 결과를 제공하기 위한 최신 기술을 찾고 있습니다.